

This page describes how to setup and operate a RAID (Redundant Array of Independent Disks) on a Linux machine. More general information about the different kinds of RAIDs can be found here.
Hardware
![]() Hardware or software RAID ? Within Linux you may operate a RAID system in software, or using dedicated hardware.
Hardware or software RAID ? Within Linux you may operate a RAID system in software, or using dedicated hardware.
- The most common form of hardware RAID takes the form of a SCSI or Fibre-Channel box, and uses a dedicated chip to perform RAID operations. Hardware RAID can also present as a PCI card. Actually, "pure" hardware RAID solutiona as PCI cards are rare animals, as most of these solutions use the CPU to perform some of their operations.
- Software RAID is totally handled by the central unit, which dispatches the data and makes all the necessary computations.
RAID operated in hardware has 2 main advantages compared to RAID done in software : it is generally faster and simpler to use. However, it is generally much more expensive.
![]() The Promise FastTrak100 TX2. This PCI card is not a true "hardware RAID" solution, as it does not feature an onboard processor. It is merely a "firmware" solution. Its main advantage is that it is cheap: it can be had for about 100 EUR. Initially 4 of our nodes were equipped with this model, which we replaced with 3ware Escalade cards (see below).
The Promise FastTrak100 TX2. This PCI card is not a true "hardware RAID" solution, as it does not feature an onboard processor. It is merely a "firmware" solution. Its main advantage is that it is cheap: it can be had for about 100 EUR. Initially 4 of our nodes were equipped with this model, which we replaced with 3ware Escalade cards (see below).
 | Features : - 2 ATA drive interfaces (master+slave) for up to 4 hard drives - support for RAID 0,1,1+0 and JBOD - hot spare capability - S.M.A.R.T. - native Linux kernel support (2.2.15 and above) - 3DM remote disk management through the WWW.
Price : - MSRP: about 100 EUR (EC) ; 85$ (US) |
Promise had released a driver module for Linux. Unfortunately it was not (yet) open-source, and the binary was available only for a small set of kernel versions, which did not match ours. So we prefered to go for the pure Linux version using the RAIDTools, although it is somewhat of a pity to use a RAID card for this. Using the RAIDTools is straightforward ; after installing the RPM, we set as a RAID 0 our 8 disks by creating a /dev/raidtab ASCII file containing
| raid-level | 0 | |
| nr-raid-disks | 8 | |
| chunk-size | 32 | |
| persistent-superblock | 1 | |
| device | /dev/hde | |
| raid-disk | 0 | |
| device | /dev/hdf | |
| raid-disk | 1 | |
| device | /dev/hdg | |
| raid-disk | 2 | |
| device | /dev/hdh | |
| raid-disk | 3 | |
| device | /dev/hdi | |
| raid-disk | 4 | |
| device | /dev/hdj | |
| raid-disk | 5 | |
| device | /dev/hdk | |
| raid-disk | 6 | |
| device | /dev/hdl | |
| raid-disk | 7 |
Next we actually create the RAID with % mkdraid /dev/md0. On powerful systems, a fairly high performance can be obtained with software RAID. With a good controller and 5-6 disks or more, RAID0 performance will generally be limited by the bandwidth of the PCI bus ( 130 MB/s on a 32bit/33MHz system, and twice this number with a 64bit/33MHz bus). RAID5 is another story. Although sequential write speeds exceeding 100 MB/s and read speeds >150MB/s can be measured in benchmarks, we noticed a dramatic drop in performance (by a factor 2 or more) once the machine was put under modest computing load.
![]() The 3Ware Escalade cards. The 3Ware Escalade products are some of the few hardware RAID PCI products with excellent support in Linux. We chose these cards to equip our machines because of their good performance in RAID5. A review of the 7450 model is available here. 5 of our cluster nodes run the 7850 model (8 drives). 4 other nodes are equipped with the more recent 7500-12 model, which support up to 12 ATA disks.
The 3Ware Escalade cards. The 3Ware Escalade products are some of the few hardware RAID PCI products with excellent support in Linux. We chose these cards to equip our machines because of their good performance in RAID5. A review of the 7450 model is available here. 5 of our cluster nodes run the 7850 model (8 drives). 4 other nodes are equipped with the more recent 7500-12 model, which support up to 12 ATA disks.
 |
Features : - 4 to 12 ATA drive interfaces (all masters) - support for RAID 0,1,5,1+0 and JBOD - hardware XOR for RAID5, improving write performance - hot spare capability - 64-bit/33MHz PCI bus - native Linux kernel support (2.2.15 and above) - S.M.A.R.T. support - 3DM remote disk management through the WWW.
Price : - MSRP: about 770 EUR (EC) ; 600$ (US) |
Installation is a breeze, just make sure that the 3Ware driver is activated in the Linux kernel, or installed as a module. Once the card and the disks are installed and configured, the array(s) are seen as /dev/sda, /dev/sdb,... like standard SCSI devices.
 |
Inside view of one of the processing/storage nodes. The full length 3Ware Escalade 7500-12 card occupies a 64bit slot of the PCI bus. The 12 250GB ATA disks are on the right of the picture. Special ATA ribbon cables (with no socket for a slave drive) from 3Ware help keeping the inside of the box relatively "clean". The fans for the disks are located beneath the front slots (so they are invisible unless the slots are removed). The power supply (top left corner of the image) is an AMD-certified 550VA model. One can also see the 2 Athlon XP/MP2400+ CPUs (horizontal fans), and the two 1GB DDR-ECC-registered memory modules. |
 |
Front view of one of the processing/storage nodes. Each slot (from 3Ware) has space for 3 disks, so that a total of 12 RAID disks plus the system disk and a CDROM device fit within 19''. The box itself is a cheap model which has been rotated to be used in a rack. Note the dust filters inside the front cover. |
Filesystems
![]() What does one expect from a good filesystem ? The filesystem is the piece of code that translates high-level concepts like files and directories into lower-level instructions to the disk(s) (put this piece of data in that block, etc.). One wants a filesystem to be reliable, fast and efficient. Another feature of a good filesystem that has become more and more important during the past years is journaling. This is due to the relative stagnation of read/write speed compared to the evolution of storage device capacity: in the early 90's, one could fill/analyse/explore the complete content of a hard drive in a couple of minutes. Now it takes several hours! Journaling is mostly useful in case of a crash. After a crash, non-journaling filesystems must analyse the full disk structure in order to identify and possibly correct erroneous informations. Obviously, this can takes hours, especially with RAIDs that store a Terabyte of data (e.g. the infamous fsck). A journaling filesystem keeps trace of the changes made as it updates the disk structure ; hence, in case of a crash, the amount of information needed to reconstruct the initial file organization is kept to a minimum, ensuring a fast resume of operations.
What does one expect from a good filesystem ? The filesystem is the piece of code that translates high-level concepts like files and directories into lower-level instructions to the disk(s) (put this piece of data in that block, etc.). One wants a filesystem to be reliable, fast and efficient. Another feature of a good filesystem that has become more and more important during the past years is journaling. This is due to the relative stagnation of read/write speed compared to the evolution of storage device capacity: in the early 90's, one could fill/analyse/explore the complete content of a hard drive in a couple of minutes. Now it takes several hours! Journaling is mostly useful in case of a crash. After a crash, non-journaling filesystems must analyse the full disk structure in order to identify and possibly correct erroneous informations. Obviously, this can takes hours, especially with RAIDs that store a Terabyte of data (e.g. the infamous fsck). A journaling filesystem keeps trace of the changes made as it updates the disk structure ; hence, in case of a crash, the amount of information needed to reconstruct the initial file organization is kept to a minimum, ensuring a fast resume of operations. ![]() The main filesystems available in Linux and how to configure them
The main filesystems available in Linux and how to configure them
- ext2fs : this is the default filesystem in old Linux distributions. It is a non-journaling filesystem. It is still fairly efficient for its age. Making an ext2fs filesystem is trivial :
- % mke2fs -t 4096 <device>
- % mount -t ext2 <device> <dir>
The "-t 4096" tells mke2fs to select 4K blocks, more appropriate for large files. In practice ext2fs is almost unusable on Terabyte scales as it is not a journaling filesystem.
- UMSDOS/vfat : the MS-DOS filesystem (non-journaling). Useful for exchanges with the Microsoft world, but you don't want this for production !
- NTFS : the Microsoft WindowsNT/2000/XP filesystem. It is a journalized filesystem. Unfortunately, current support for NTFS in Linux is read-only.
- ext3fs : this is a journalized version of ext2fs, whose main interest is to yield a disk structure which is still useable on older systems. An ext3fs filesystem is created using
- % mke2fs -j -t 4096 <device>
- % mount -t ext3 <device> <dir>
- ReiserFS : originally developed for Linux only, it was also one of the first to support journaling. It excels at manipulating very large directories with small files. The "notail" option in the mounting can bring additional speed at the expense of a lesser efficiency in disk usage :
- % mkreiserfs -f -f <device>
- % mount -t reiserfs -o notail <device> <dir>
- JFS : this is a Linux port of IBM's journaling filesystem. It is extremely efficient for sequential reading, but fairly slow at writing.
- XFS : SGI's journaling system has been ported to Linux. The specs are impressive, allowing filesystems of up to 2000 PetaBytes on 64bit machines. One small complaint about XFS, is that file deletion can be quite slow. XFS is not part of the generic Linux kernel; however, patches (or full kernels via CVS) are available on the SGI website. One must be careful not to compile the XFS code with the 2.96 version of the gcc compiler (it has been reported to lead to hickups during XFS disk access). Fortunately, almost all recent Linux distributions have native support for XFS, which allows one to adopt XFS even for the system disk partitions. Once patched and recompiled with XFS support, the filesystem is created using
- % mkfs -V -t xfs -f <device>
- % mount -t xfs <device> <dir>
This is just an example; see the man page of mkfs.xfs for an explanation of all the available options. XFS is a high performance filesystem. With default settings it already tops all other filesystems for sequential I/O's on large files. Nevertheless some extra performance ( 10%) can be gained by telling XFS that you are using a RAID with a given stripe-size. With our 3Ware RAID5 systems (stripe-size=64k, max 2TB/array) we obtained the best performance using the following mkfs options : % mkfs -V -t xfs -f -d su=64k,sw=8 <device> The su/sw parameters can also be modified at mount time (see the mount man page).
![]() Filesystem size limit. The Linux kernel 2.4.x or older is limited to 2TB on 32-bit machines. This is a fairly "hard" limit, corresponding to 2^32 512-byte blocks, and it cannot be easily overcome. At TERAPIX we tried all kinds of tricks to pass this limit without success. In addition, it is important to know that most RAID firmwares at the time of writing (Feb 2003) also limit filesystems to 2TB in size. Actually, in the Windows world, NTFS is also limited to 2TB, which does not help in pushing developments to remove this limitation in hardware. The situation is likely to evolve by mid-2003 with the release of Linux kernel 2.6, which supports larger filesystems. Until then, it will most often be useless to combine more than 8 (for RAID0) or 9 (for RAID5) 250GB disks in a RAID array.
Filesystem size limit. The Linux kernel 2.4.x or older is limited to 2TB on 32-bit machines. This is a fairly "hard" limit, corresponding to 2^32 512-byte blocks, and it cannot be easily overcome. At TERAPIX we tried all kinds of tricks to pass this limit without success. In addition, it is important to know that most RAID firmwares at the time of writing (Feb 2003) also limit filesystems to 2TB in size. Actually, in the Windows world, NTFS is also limited to 2TB, which does not help in pushing developments to remove this limitation in hardware. The situation is likely to evolve by mid-2003 with the release of Linux kernel 2.6, which supports larger filesystems. Until then, it will most often be useless to combine more than 8 (for RAID0) or 9 (for RAID5) 250GB disks in a RAID array.
Benchmarking and Tuning
![]() 3Ware Escalade 7500-12, 9x250GB disks (2TB effective)
3Ware Escalade 7500-12, 9x250GB disks (2TB effective)
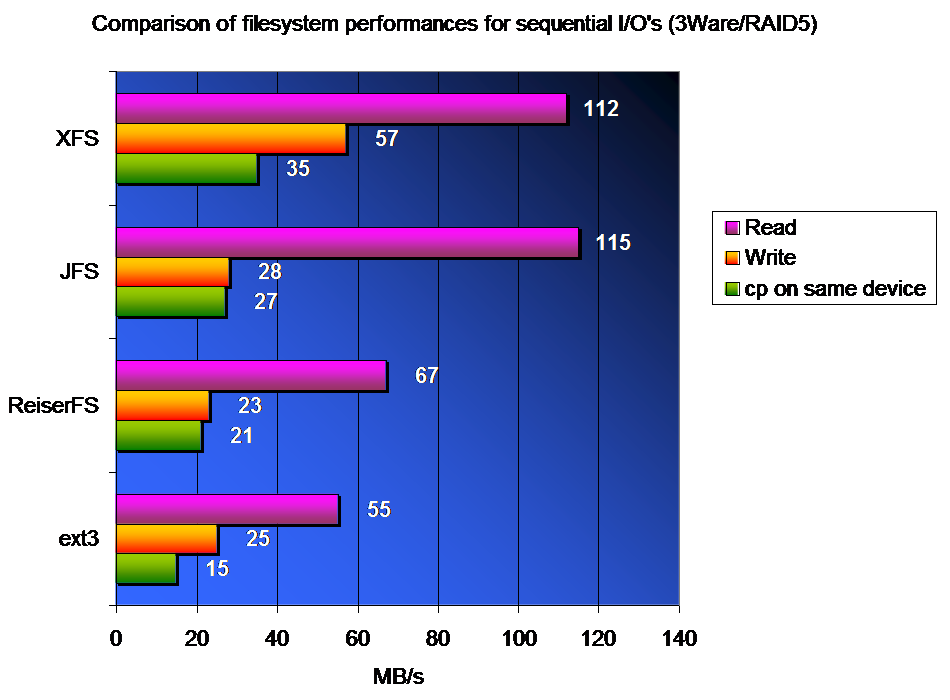
We were interested in measuring the performance of our arrays in RAID5 mode, which is certainly the most demanding in system resources. For wide-field image processing we are mainly concerned with the sequential transfer rate of large files. The graph one the left shows the relative performance obtained in 3 house-made tests for various filesystems. Read and Write tests are performed with PerfIO 1.1. This program generates random data in a huge memory buffer (512 MB) which is then used to measure the asymptotic transfer rate with large chunks. The rest of the available memory is filled with random numbers to prevent the system from using it as a cache. The 3rd test just measures the transfer rate obtained by doing a cp of a large file (800 MB) in the same partition. In all cases, the CPU usage is less than 40%. Many people use the Bonnie++ program for benchmarking storage devices. Bonnie++ is a reliable and superior tool that measures the ultimate throughput that can be obtained from a filesystem. This is done using some "intelligent" writing and reading routines which allow to optimize sequential transfers between disk and memory. The downside of this approach is that it often yields transfer-rates that cannot be reached with the conventional I/O calls (fread(), fwrite()) found in scientific codes. Typically, read/write transfer rates displayed here are underestimated by about 20% compared to what Bonnie measures.
In our tests, XFS is the clear winner when it comes to throughput. Note that higher throuputs may be obtained by combining 2 or more 3Ware cards : see this link and this one.
![]() Tuning I/O parameters in Linux. In some contexts, performance of disk I/O's under Linux can be improved by modifying the parameters in /proc/sys/vm/. The first set of parameters of interest is contained in /proc/sys/vm/bdflush. By modifying these numbers (this can be done at run-time, or at each boot by adding a line in /etc/sysctl.conf), one can tune the system to make it behave more like a server or more like a workstation. With kernel 2.4, /proc/sys/vm/bdflush is a string containing 9 numbers ; for instance
Tuning I/O parameters in Linux. In some contexts, performance of disk I/O's under Linux can be improved by modifying the parameters in /proc/sys/vm/. The first set of parameters of interest is contained in /proc/sys/vm/bdflush. By modifying these numbers (this can be done at run-time, or at each boot by adding a line in /etc/sysctl.conf), one can tune the system to make it behave more like a server or more like a workstation. With kernel 2.4, /proc/sys/vm/bdflush is a string containing 9 numbers ; for instance
- % echo 100 5000 640 2560 150 30000 5000 1884 2 > /proc/sys/vm/bdflush
The first number, called nfract, is the most important. Basically it states the percentage of modified ("dirty") I/O buffers in memory that must be reached before being flushed from/to disk. The lower the nfract, the smoother operations go for single disk accesses: data are being flushed as they are written/read. However this becomes pretty inefficient when several tasks access the disk simultaneously. Inversely, a high nfract makes multiple disk accesses more efficient, but some time is lost for single accesses. The default value for nfract depends on your Linux distribution. For instance, nfract is 40 (%) in most Redhat distribs, 30 in Mandrake 9.0, and 100 in some others. Our tests show that a nfract of 30 provides the best performance for single image processing tasks. In our tests we did not find much improvement/degradation by changing the other parameters, so we would suggest to leave them with their default values. Increasing the /proc/sys/vm/min-readahead (to, say, 128) and /proc/sys/vm/max-readahead (to, say, 512) can be beneficial for devices with a high throughput. Another way to optimize transfer-rates for some Linux applications is to tune the so-called disk I/O elevators, which allow one to trade I/O latency for throughput. This can also be done at run-time, on a device basis, using the /sbin/elvtune command (part of util-linux). /sbin/elvtune sets both the read and write latency. The default values for read_latency and write_latency are generally 8192 and 16384, respectively. One can for instance change them to 2048 and 4096 with % /sbin/elvtune -r 2048 -w 4096 <device>
In our experiments with 3ware products we did not notice a significant improvement from changing read_latency and write_latency for single I/O operations.